GreenFit AI technical details
Table of contents
Workflow
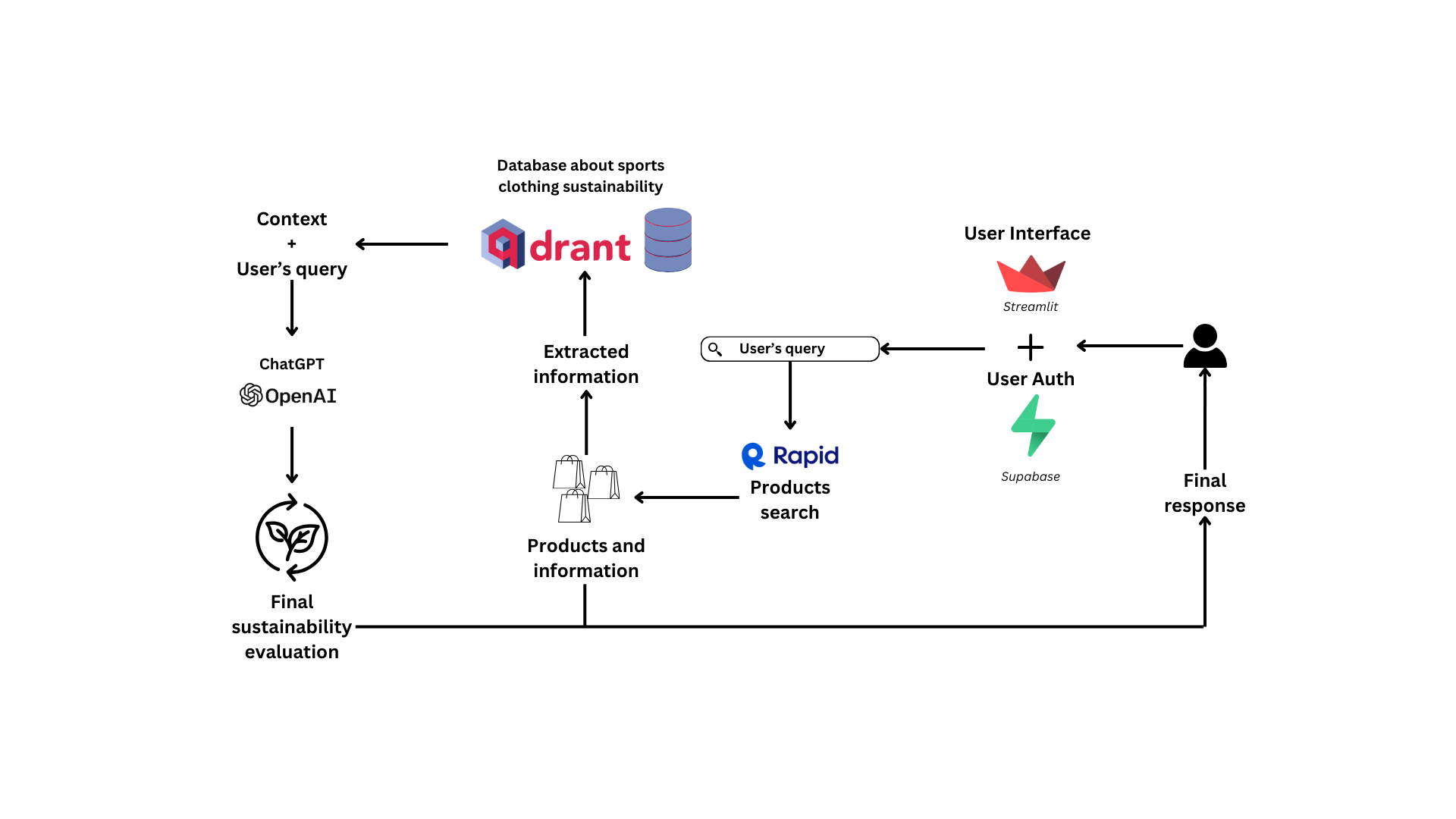
Authentication and user management
Code reference here
Authentication and user management are achieved through the streamlit_supabase_auth_ui. The authentication UI, based on Gauri Prabhakar’s login interface, combines the power of Supabase PostgreSQL databases with the seamless frontend components from Streamlit, connecting it also to the e-mail notifications service offered by Courier.
Upon registration, the user name, email and (hashed) password will be stored in a Supabase database: they will also receive a confirmation e-mail by Courier. When the user logs in, we send a request to the database, seeing if their password and username match with the stored ones. Users can also change their password if they lost it.
Product search functionalities
Code reference here
Product search functionalities are a two-step process:
- The natural language query from the user gets transformed into a browser-optimized query:
gtp-4o-minitransform the query into a list of keywords, which is retrieved thanks to Langchain+Pydantic structured output schemas and parsers. - The keywords are used to search Google Products: thanks to Rapid Product Search API, we send a request to Google Products with the extracted key-words. This returns a list of a user-specified number of products, with each entry of the list being a JSON/dictionary object.
Vector Database and Retrieval Augemented Generation
Code reference here
We extract metadata from the products, such as price, title and description. We combine these metadata to search a curated database containing sustainability information on sport clothing brands. This information was vectorized and is stored inside an on-cloud instance of a Qdrant vector database. We perform semantic search on the database and we retrieve the context that will be given to ChatGPT for its sustainability scoring evaluation.
Sustainability scoring
Code reference here
Sustainability scoring is achieved thanks to gtp-4o-mini, which, based on the products information and on the context it is given, gives the products a score out of 10 for three sustainability fields:
- Renewable energy usage
- Low-carbon materials usage
- Overall sustainability
These scores also come with the reasons why gtp-4o-mini assigned them.
Collecting ordered scores and the reasons for them is achieved through Langchain+Pydantic structured output schemas and parsers.
Frontend, secrets management and serving
Code reference here
The frontend is managed with Streamlit. It is a one-page application with:
- A text input area for the user query
- A number-based input bar to define the maximum number of results
- The demo application on HuggingFace Spaces also has two other text input areas, for the Rapid Product Search API key and for the OpenAI API key.
It displays results in Markdown format.
The style of the application is defined in a .streamlit/config.toml file.
All the secrets are defined in a .streamlit/secrets.toml file and are also securely stored under HuggingFace Spaces secrets.
The app can be directly deployed on Streamlit (connecting it from GitHub), but we preferred keeping our demo on HuggingFace Spaces.